







Comprehensive and timely activity logs are powerful tools that enable security monitoring and incident response in the cloud. However, while studying Azure logs, our researchers noticed many deficiencies that complicate understanding of user actions and may even let an attacker slip by. In this post, we will discuss these issues and their impact on the work of the blue team.
Why we study Azure Monitor Logs
Before discussing provider-specific details, we should note that logs carry different significance in cloud and on-premises environments.
Administrators have some choice in on-premises setups: You can tap into network traffic to monitor activity or collect logs on the network edge and on individual machines. The logging and monitoring solutions (hardware and software) are replaceable, and if a particular vendor product does not perform well, another can be installed.
In the cloud, you do not have those options — the provider fully controls available logs. If they are of high quality, great! But if there are issues, you’re at the mercy of the provider's willingness to fix them. You can either raise them with the vendor and hope for the fix or try to work around them, where possible.
While monitoring activity in the cloud environment, there are several expectations:
- No unannounced changes to log structure or content
- Timely logging of events
- Complete and accurate log records (with no missing or broken values)
- Full documentation for logged events
- An easy way to correlate events and user sessions between different logs
- A set of threat indicators to use in incident analysis
When analyzing activity, the following data needs to be consistently available in all log sources and for all event types:
- Operation names and details
- User identity and session information
- IPs
- Geolocation
- Device information
- Threat and reputation indicators
Essentially, you want to be able to tell who did what and when (and what else they did). Unfortunately, these expectations are not always fulfilled in Azure logs.
How we monitor events in Azure
Azure has a mature set of event analysis and monitoring products:
Microsoft Sentinel is a native SIEM product that ingests logs from various sources. It has a set of built-in detections and allows us to define custom ones.
Azure Log Analytics is a log analysis platform that is great for ad-hoc investigations of suspicious events.
They both support Kusto — a powerful log query and analysis language. In addition, you can use third-party solutions to monitor and interpret the logs.
Azure logging infrastructure is vast and has dozens, if not hundreds, of log sources. It would be impossible to discuss all of them, so let’s concentrate on logs generated by Azure AD (now Entra ID), Azure's IAM solution, and Microsoft 365, a cloud SaaS office suite.
Entra ID logs cover:
- Sign-ins – several logs covering sign-inactivity of interactive and non-interactive users, service principals, and managed identities
- Audits – a record of significant directory operations
- Provisioning - data on the provisioning of users by third-party services
These logs are accessible through Graph API and currently exist as a base version (1.0) and a Beta, which have different schemas.
Microsoft 365 activity logs are consumed through the Management Activity API, which provides several logs for different types of events:
- Audit.AzureActiveDirectory - events from the Entra ID service (similar to what is available via Graph API), such as assign-ins and directory changes
- Audit.Exchange - Exchange events
- Audit.SharePoint - SharePoint activity
- Audit.General - most other actions that do not fit into any of the other logs
- DLP.All - Data Loss Prevention events
Known Azure Monitor Log issues
Now that we’ve explored the importance of Azure Log Monitoring, let's delve into some issues we’ve encountered in these logs. Awareness of them may help you build better analysis queries and waste less time wondering why things behave the way they do.
Specific challenges that should be on every security analyst’s and architect’s radar include:
- Fluid schema
- Log flow
- Event delays
- Missing events
- Logging tax
- Events that are never logged
- Deficient documentation
- Unannounced changes
- ID inconsistencies
- IP inconsistencies
- Geolocation inconsistencies
- Device information inconsistencies
- Broken values
Let's look at each one in more detail.
Fluid schema
The schema in some of the logs (e.g. Management Activity API) is"fluid." This means that a unique parameter in a new operation will be added to the log as a new column.
This makes it challenging to manage, even for Log Analytics. (We’ve observed it showing errors about a "limit of maximum 500 columns reached"). If you’re looking to consume events in an external SIEM, you may have to be selective about which columns to consume, and it's impossible to predict new ones that Azure adds.
A better method would have been a static schema in all logs, with structure fields (e.g. in JSON) added to handle variability.
Log flow
There are occasional log outages in Azure. In fact, we saw several over the past few years. While one lasted several weeks and was discovered accidentally, Microsoft is generally good at notifying customers in such situations.
The problem is that during an outage, you may be utterly blind to any activity in the environment. If you also happen to miss the outage announcement, nothing will indicate that there is a problem. It’s essential to stay on top of service health in Azure and possibly invest in some monitoring solution that tracks log flow.
Outages can also be deliberate. Logging configuration is controlled in-band, and a compromise of an administrator's account may lead to attacker disabling logging on a large scale (e.g. via Set-AdminAuditLogConfig) or in a more fine-grained and stealthy fashion (e.g. through Set-Mailbox -AuditEnabled).
Monitoring log flow and configuration changes is essential to mitigating such issues. Only a few authorized users must be able to change logging settings. It would be preferable if Azure were to add more controls to logging configuration because of significant adverse consequences stemming from accidental or deliberate log disabling.
Event delays
Microsoft publishes expected times for its log event availability. Graph API ingestion time is claimed to be under 3 minutes. In our experience, it may take up to 30 minutes for the events in those sources to appear.
The advertised typical availability for the Management ActivityAPI events is between 60 and 90 minutes. In reality, the delays that we observed are more significant. Here are some maximum numbers that we captured recently - certain times far exceed 24 hours (max_delay column contains maximum time seen between event creation and its availability in the log):

These kinds of delay times are unsustainable. Some attackers move extremely quickly. If we factor in the time required for processing by detection tools, ingestion by external SIEM, and reaction by SOC personnel, it becomes clear that, in many cases, the blue team will be late — almost by design.
The more attackers automate their tooling, the worse the situation will get. Azure needs to prioritize fast log availability. Otherwise, defenders can only react to incidents, not stop them. Event delays are even harder to deal with when log records are forwarded into an external SIEM. Log API calls take time ranges as parameters, so you would either have to accept record loss or query overlapping time ranges and remove duplicate records in order not to miss late events.
Missing events
Some event types may be found in more than one log. For example, sign-in records are available in both Graph API and Management Activity API. Compare records for the same event in both sources, and occasional differences will be revealed.
Consider the following examples taken from a recent incident investigation. While they all correspond to the same actions by an attacker, the records logged do not match exactly:
Graph API (beta -in Azure Portal):

Graph API (v1.0):

AuditAzureActiveDirectoryin Management Activity API:

This type of inconsistency is hard to reproduce and explain, but you need to be aware of it when doing log analysis. Records may get lost, and analysis of multiple logs may be necessary to build a more complete picture of what transpired.
Logging tax
Many logging event types and details are only available with higher-paid tiers (e.g. E5 and P2). Some examples include MailItemsAccessed events, risk details in the sign-ins log, and others. This presents a dilemma for many customers — it means choosing between lower costs or better visibility into activities in your environment.
This is not a good choice to be forced to make and, in our opinion, basic security features (such as logs) should be available to all cloud customers. As U.S. Senator Ron Wyden recently put it, "Charging people for premium features necessary to not get hacked is like selling a car and then charging extra for seatbelts and airbags."
This lack of visibility has caused difficulties in many Vectra AI customer incidents we’ve had to investigate. A recent public breach by APT Storm-0558 that Microsoft itself had to deal with has brought this issue into the open. As a result of that incident, Microsoft agreed with CISA to expand access to logging to all customers this fall.
Hopefully, things will improve soon. In the meantime, you need to make sure the logging you have access to through your license is adequate for your organization’s IR needs. If not, it’s time for an upgrade. When essential data is unavailable, some of it (e.g., IP reputation and geolocation information) could be acquired from 3rd party sources.
Some events that are never logged
Azure is a "reconnaissance paradise," with "get"-type events that correspond to reading configuration and data that are, with rare exceptions, not logged. As of October 2023, a new log that records Graph API calls was introduced and does cover some of the recon operations. However, enumeration through other APIs remains invisible to defenders.
This means that when an attacker gets access to the cloud environment, they can enumerate most information — users, services, configuration — without being seen by defenders. This presents a big blind spot — in our testing, most open-source M365/AAD enumeration tools did not leave any trace in the logs.
It’s unclear why the decision not to log such events was made, though it may be to save space. Unfortunately, no option to have such logging enabled exists, even if the customer wants to see these kinds of events. Which means you’re in the dark until attackers start making changes to your environment.
Deficient documentation
While the Azure APIs are documented reasonably well, log event documentation is lacking. For many events, the only thing documented is the operation name, but individual fields and their meaning are often a mystery. You have to hunt through blogs and discussion boards to try and interpret what’s happening.
In addition to a field's purpose being unclear, individual data values are sometimes poorly documented, too. We have seen specific authentication types, status codes, operation subtypes, and other data without description. Even a thorough research effort did not bring clarity for some of those values.
Because we do not understand some fields and values, we cannot monitor and interpret them during incident investigation and response.
Unannounced changes
As cloud functionality evolves (as it frequently does), new event types appear unannounced in the logs. For example, a new error code was added for password less sign-in failures that we recently documented. The Vectra AI Security Research Team had to spend time investigating it before we could understand what triggered it, and until then, our monitoring queries were blind to it.
What's more troubling is that existing events may also disappear or change their format. Some recent examples include:
- MailboxLogin event that we were tracking and that silently disappeared from Exchange logs.
- Sign-in errors for non-existing usernames that we tracked to catch early stages of recon activity and were no longer written to sign-in logs.
When you have monitoring and analytics queries looking for specific events, these changes will make them stop working without warning. This is the worst kind of failure — when you don’t even know there’s a problem. You may need to invest in logic to monitor log integrity and keep a close eye on changing log contents and documentation. Unfortunately, most defenders are too busy to spend time on that.
ID inconsistencies
User IDs are not always "stable." Depending on the context and type of operation, the same user can show up in the logs under different "user principal names" (UPN). For example, your user could be logged as:
- john.smith@company.com
- John.Smith@company.com (note the difference in letter case)
- AN045789@company.com
M365 Exchange throws a wrench in the works by adding legacy names such as the following (plus others):
"NAMPR07A006.PROD.OUTLOOK.COM/Microsoft ExchangeHosted Organizations/ company.onmicrosoft.com/0cf179f8-0fa4-478f-a4cc-b2ea0b18155e"on behalf of "NAMPR07A006.PROD.OUTLOOK.COM/Microsoft ExchangeHosted Organizations/ company.onmicrosoft.com/JohnSmith"
In name variability cases, connecting different events to the same user becomes difficult. While correlating events by the UPN may be the first impulse, doing it by the unique internal ID may be a more robust strategy (but still not foolproof).
The difficulties continue:
- Different names in different logs may have overlapping field names with different meanings. For example, user_id will mean a user GUID in one log and a UPN in another.
- User IDs may have values representing user first and last names, application names, application GUIDs, and other unusual names and unique IDs.
- User IDs may be empty or contain useless names like "Not Available", "Unknown","No UPN":
As a defender, you have to be ready to see this (less than helpful) information in the user identity fields and build query functionality accordingly.
IP inconsistencies
A valid IP address is a basic expectation for every log record. While valid IPv4 and IPv6 addresses are available in log entries most of the time, sometimes we see IPs that are hard to understand and use in analysis:
- IPs with port numbers (both v4& v6)
- Empty IPs
- Local & private IPs:127.0.0.1, 192.168.*, 10.*
- All-zero IPs: 0.0.0.0
- IP masks instead of IPs:255.255.255.255
- IPs that correspond to Azure infrastructure, not the user performing the operation
IPs cannot be correlated to sign-in records for some of the operations, which complicates incident analysis. IP risk and reputation indicators may occasionally be available but are subject to "logging tax."
As a defender, you should expect these special cases when writing hunting queries and alerts and accommodate them in your logic.
Geolocation inconsistencies
Currently, Microsoft only provides geolocation for sign-in records. This would have been helpful for other log sources because you can’t always connect activity to specific sign-in records.
This feature is not perfect. On occasion, there are hiccups:
- The same IP resolves to multiple locations (most likely related to mobile devices).
- Records are geolocated incorrectly en masse.
- Geoinformation is missing:

Geolocation is also easily fooled by TOR, VPNs, proxies and cloud provider IPs – and should be taken with a grain of salt.
Device information inconsistencies
Device details are complex for Microsoft to determine (unless we’re dealing with an enrolled device). Platform and browser information is ordinarily parsed from the User Agent (UA).
Unfortunately, there are inconsistencies here, too:
- Some logs parse the UA and provide it piecemeal, yet others give the entire UA string (which you have to interpret)
- Device information is not available in all logs
- Parsed values are not always consistent (e.g. “Windows” vs. “Windows 10”)
Attackers can easily forge User Agent, but it’s still valuable for investigations as not all are disciplined enough to change it inconspicuously.
Broken values
Some log fields have complex structures (e.g. JSON), and hunting and monitoring queries need to parse them to refer to specific sub-fields.
Occasionally, these values get cut off due to size limits, resulting in broken structures. For example, consider the following value logged for the Set-ConditionalAccessPolicy operation. A part of it is cut off and replaced with three periods ("..."), which will confuse the JSON parser:
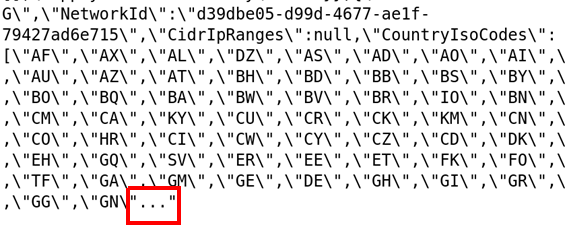
Monitoring queries that encounter such records will fail, resulting in blind spots.
In such cases, relying on the values being parsed correctly may not be the best strategy, and substring searches may work better.
What will it take to improve log quality?
We’re not alone in criticizing Azure log quality(similar issues were previously raised by CrowdStrike and EricWoodruff), and we can only speculate as to why so many of them exist.
Logs usually take the back seat, priority-wise, to other features in software development. Back-end service features can be sacrificed when the development team is under the gun to release primary product functionality.
In enormous product ecosystems such as Azure, multiple independent(and sometimes, legacy) products are brought together. Having all of them provide a good signal in a common logging architecture may be difficult and this functionality is not exactly "customer-facing," so complaints about it may get deprioritized.
Whatever the reason, the absence of alternatives in a cloud environment makes log issues much more severe than they would have been in a traditional on-premises setup. Aside from being aware of log deficiencies and attempting to work around some of them, defenders do not have other options. Microsoft owns this functionality, and it’s up to them to improve it.
We believe that a number of non-intrusive changes can (and should)be made by the Azure team:
- All events, fields and enum values should be fully documented to take the guesswork out of log analysis.
- Log structure and contents should be treated like an API — any changes that could break log querying functionality should be introduced in a controlled way, and customers should be given time to accommodate changes.
- All additions and (especially)removals of logged operations must be clearly announced.
- Records must be delivered in a much more timely fashion than they are today — in seconds rather than minutes or hours — and events should not be delayed or arrive out of order.
- All logged values should be useful, correct, non-ambiguous.
- Logs should contain rich information that’s useful for incident response (for example, IP reputation).
Ideally, refactoring the logging architecture to make it more streamlined (similar to what is available in AWS and Okta) would be beneficial.
The takeaways for red-teamers
We have so far only talked about the difficulties these issues pose for your team. But it’s important to remember that any defender's loss is the attacker's gain. Competent black hats, APTs and red-teamers can take advantage of the peculiarities of Azure logging to hide their actions and complicate blue-team efforts.
Here are some of the techniques attackers could employ:
- Making use of unusual operations that are less documented or understood
- Executing actions that inject broken or undocumented values in the logs to complicate analysis
- Connecting from locations for which IPor geolocation information is logged incorrectly
- Timing operations to take advantage of ingestion delays or to complicate the discovery of related events
Of course, more research would be needed to turn any logging deficiency into a robust evasion technique.
Your job as a defender is hard. Trying to detect and remediate attacks quickly is a big undertaking, and it gets even more laborious when you have to mind-log problems and work around them.
The promise of better security in the cloud is not a pipe dream, and one of the ways to help achieve it is to deliver high-quality logging. While providers do have the power to make this happen, they may lack the incentive to make it a high-priority goal. That’s where we come in. The more the security research community exposes, and the more pressure we apply, the closer we can get to improving log quality.
Want to join the conversation? Engage with the Vectra AI Security Research Team directly, on this blog post and other topics, on Reddit.